The puzzle once baptized as the hardest logic puzzle ever was described in an article by George Boolos, published in The Harvard Review of Philosophy in 1996, where Raymond Smullyan is mentioned in the very first sentence as the original author. How the problem was originally formulated, and its exact attribution, are not entirely straightforward, but we will not dwell on historical technicalities here. Without further ado, let’s unveil the challenge:
Assumptions
Before we proceed, let’s take a look at a few clarifications mentioned by Boolos himself in his article:
-
Answers given by the Goddess of Fate may be treated as the result of a fair coin toss between Da and Ja. Since we are expected to provide a strategy that works with certainty, we must always consider both possibilities anyway.
-
You don’t have to question each goddess exactly once.
-
The choice of which goddess to question may depend on previous answers.
One extra detail worth addressing upfront is that some solutions attempt to ‘hack’ the problem by posing paradoxical questions with no well-defined answer, for instance:
\[\text{Is this statement false?}\]To rule out these cases, let us adopt the convention that any such question makes a goddess wrathful, and she responds with a randomly chosen answer. The same applies to questions that fall outside the scope of her vast knowledge.
Key Difficulties
This problem is an excellent case study in how to decompose a larger task into a collection of smaller, more manageable ones.
We can quickly identify the core challenges posed:
-
We need to deal with the lying goddess.
-
We do not know whether Da means Yes or No.
-
One goddess provides random answers, shrouding everything in an extra layer of fog. Even if we somehow learned the meaning of Da/Ja and forced the Goddess of Lies to speak truthfully, it would still not be obvious how to proceed.
For each of these points, we can construct a toy example that isolates the difficulty. Later, we combine these pieces into a solution that emerges naturally.
Two Guardians
The first issue we resolve is how to avoid getting tricked by the Goddess of Lies. It is best to start with a simpler puzzle, one that is arguably even more well known than the problem of three goddesses. I particularly like the classic two guardians lore, though many have encountered it in the form of the Knights and Knaves problem. It goes as follows:

Solution of Puzzle 1: Ask any guardian the following question: If you were the other guardian, which one of you would you point to as the one holding the key? Then simply choose the guardian not indicated in the response.
Warm-up Questions
Let us ponder for a moment the dynamics behind the solution. It is natural to start by analyzing some obvious questions. A tempting first try:
T: Yes.
F: Yes.
This doesn’t look very helpful. Even if both guardians answered, we would gain no information. Let’s try a different approach:
T: Yes.
F: No.
Great. Now we know which one is the truth-teller, but we still have no idea who has the key. It is a small step forward, though. How about:
T: No.
F: No.
In this case, we can conclude that the liar has the key, but we still cannot tell which guardian is which, so the key remains out of reach.
Putting Things in Form
Let us introduce some notation and formalize the discussion a bit. Assume that $x$ is a sentence and $v(x)$ is its logical value, so $v(x)=1$ if $x$ is true and $v(x)=0$ if $x$ is false. The general form of the question we ask is:
\[\text{Is it true that $x$?}\]For instance, in one of the examples above we had $x = \text{“2+2=4”}$. In such cases, we expect one guardian to answer Yes and the other one to answer No. However, we also saw that the question “Do you have the key?” can result in two No’s (or two Yes’s). This happens because we are effectively asking two different questions, depending on the recipient. To fully align with the formalization, we may label the guardians as Guardian A and Guardian B, and consider a statement such as
\[x = \text{"Guardian A has the key."}\]Now the logical value of the statement remains independent of the recipient. In practice, however, we will sometimes use simpler formulations such as “You have the key” and ignore this detail.
Let us refer to the truth-telling guardian as $T$ and the lying one as $F$. The solution to the two-guardians puzzle revolves around the idea of forcing both guardians to behave like liars. If $T$ is asked to answer as $F$ would, the response must be false. On the other hand, if $F$ is asked to answer as $T$ would, the response must also be false.
Let’s describe this reasoning using our rudimentary formalism. In this framework, it is more convenient to take the opposite perspective and arrange things so that both guardians effectively behave like truth-tellers:
-
If we ask $T$, we can simply ask whether $x$ is true.
-
If we ask $F$, we instead ask whether $\neg x$ is true.
We can combine these two points into a single question. Define
\[\varphi(x) := (x \, \wedge \, \text{You are $T$}) \, \lor \, (\neg x \, \wedge \, \text{You are $F$}).\]Now, we ask any guardian:
\[\text{Is it true that $\varphi(x)$?}\]There are four possible cases: the guardian we ask may be truthful or not, and $x$ may be true or false. The resulting answers are summarized below. The ticks and crosses indicate whether $\varphi (x)$ itself evaluates to true $(\checkmark)$ or false $(\times)$.
\[\begin{array}{c|c|c} \text{Input} & x & \neg x \\ \hline T & \text{Yes } _\checkmark & \text{No } _\times \\ F & \text{Yes } _\times & \text{No } _\checkmark \\ \end{array}\]Any Yes answer means that $v(x)=1$, regardless of which guardian we ask. This fully neutralizes the liar. Now we only need to choose $x$ appropriately, for instance “You have the key.”
How Much Can a Yes/No Tell You?
At this point, it may be helpful to recall how an answer carries information.
Since each answer is Yes/No, we can think of it as a single bit of information, either $1$ or $0$. In this sense, a sequence of answers to, say, 3 questions can be represented as, for example, $101$ or $110$. In general, asking $k$ questions yields $2^k$ possible sequences of answers, each corresponding to a distinct state. On the other hand, if the number of states is $n$, then we need at least $\lceil \log_2 n \rceil$ questions to distinguish between them.
Example
We have 5 barrels of wine, one of them poisoned. A servant knows which one it is and, eager to undo his ‘mistake’, answers truthfully to any Yes/No question. Are 2 questions enough to identify the poisoned barrel? Let’s see: we only get 2 bits of information, so at most we can distinguish between 4 possible states. For instance, we could assign:
\[\begin{aligned} 00 &\mapsto \text{Barrel 1 is poisoned.} \\ 01 &\mapsto \text{Barrel 2 is poisoned.} \\ 10 &\mapsto \text{Barrel 3 is poisoned.} \\ 11 &\mapsto \text{Barrel 4 is poisoned.} \end{aligned}\]That leaves Barrel 5 with nowhere to go. All 2-bit sequences are already taken. So either we ask another question, or we accept that some outcomes must correspond to more than one possibility. For example:
\[11 \mapsto \text{One of the Barrels 4 or 5 is poisoned.}\]If the servant answers Yes to both questions, you can still safely drink from 3 barrels. Similarly, even a single question is enough to guarantee at least 2 clean barrels by assigning:
\[\begin{aligned} 0 &\mapsto \text{One of the Barrels 1 or 2 is poisoned.} \\ 1 &\mapsto \text{One of the Barrels 3, 4, or 5 is poisoned.} \end{aligned}\]Better than nothing.
States to Consider in the Smullyan Puzzle
In the main puzzle, we need to assign labels to three goddesses, which gives us $3!=6$ possible states. This means that $\lceil \log_2 6 \rceil = 3$ questions are the absolute minimum to distinguish between them, even if all the goddesses always spoke truthfully. Similarly, in the Two Guardians puzzle, we only needed to distinguish between 2 possible states, so a single question was enough.
Language of Gods
Another complication is that the goddesses from the Smullyan puzzle do not simply answer Yes/No, but rather Da/Ja. Let us isolate this difficulty and look at a simpler problem.
Let us label the aliens, not very creatively, as Alien A and Alien B. Notice that we cannot determine the logical values of the following two statements at the same time:
-
Da stands for Yes.
-
Alien A has the key.
Each statement may be true or false, giving 4 possible cases in total. Since we receive only a single bit of information, we must identify which alien has the key without learning the meaning of Da or Ja. In fact, we can follow the same approach as in the previous subsection. Define
\[\psi(x) := (x \, \wedge \, \text{Da is Yes}) \, \lor \, (\neg x \, \wedge \, \text{Da is No}).\]We now ask whether $\psi (x)$ is true. The possible answers are summarized below.
\[\begin{array}{c|c|c} \text{Input} & x & \neg x \\ \hline \text{Da is Yes} & \text{Da } _\checkmark & \text{Ja } _\times \\ \text{Da is No} & \text{Da } _\times & \text{Ja } _\checkmark \\ \end{array}\]We reached a configuration where Da simply indicates that the underlying question $x$ is true. The rest follows easily, since a single bit is enough to tell whether Alien A or Alien B has the key.
Even Aliens Can Lie
Take the same alien puzzle from the previous section, but add the extra assumption that one of the aliens always lies. As before, we label them as $A$ and $B$, though we do not know which is which. This gives us $2^3=8$ possible cases: an alien may lie or not, Da may mean Yes or No, and the key may be held by either alien.
To recover the answer to any question of our choice, we combine the constructions from the previous sections into a single, slightly monstrous sentence:
\[(\psi \, \circ \, \varphi ) (x) = (\varphi (x) \, \wedge \, \text{Da is Yes}) \, \lor \, (\neg \varphi (x) \, \wedge \, \text{Da is No}).\]In other words, we first evaluate $\varphi (x)$, which neutralizes the liar, and then use $\psi$ to account for whether Da means Yes or No.
If one wishes to fully expand this expression, we obtain:
\[\begin{aligned} &(x \, \wedge \, \text{You are $T$} \, \wedge \, \text{Da is Yes}) \, \lor \, (\neg x \, \wedge \, \text{You are $F$} \, \wedge \, \text{Da is Yes}) \\ \, \lor \, &(x \, \wedge \, \text{You are $F$} \, \wedge \, \text{Da is No}) \, \lor \, (\neg x \, \wedge \, \text{You are $T$} \, \wedge \, \text{Da is No}) . \end{aligned}\]Here is how the possible answers play out:
\[\begin{array}{c|c|c} \text{Input} & x & \neg x \\ \hline T \, \wedge \, \text{Da is Yes} & \text{Da } _\checkmark & \text{Ja } _\times \\ T \, \wedge \, \text{Da is No} & \text{Da } _\times & \text{Ja } _\checkmark \\ F \, \wedge \, \text{Da is Yes} & \text{Da } _\times & \text{Ja } _\checkmark \\ F \, \wedge \, \text{Da is No} & \text{Da } _\checkmark & \text{Ja } _\times \end{array}\]The key observation is the pattern: regardless of who we ask or what Da means, the answer Da is returned exactly when $x$ is true, and Ja otherwise.
Solution!
We have three goddesses, denoted by $T$, $F$, $R$ (for True, False, and Random): the Goddess of Truth, the Goddess of Lies, and the Goddess of Fate.
Since we do not know which is which, we label them in arbitrary order as $G_1$, $G_2$, $G_3$. Our task is to identify the correct assignment among the 6 possibilities. For example, one such assignment is:
\[\begin{aligned} G_1 &\mapsto F \\ G_2 &\mapsto T \\ G_3 &\mapsto R \end{aligned}\]We now apply the construction developed in the previous sections. To determine whether a statement $x$ is true, we ask:
\[\text{Is it true that $(\psi \circ \varphi)(x)$?}\]This way we neutralize the difficulties arising from the fact that one goddess always lies and that we do not speak the language of gods. We have effectively reduced the main puzzle to a simpler one:
Let us first observe that if $R$ also always spoke truthfully, the puzzle would become easy. We could simply split the 6 possible assignments into two groups of three, say Group A and Group B, and ask:
\[\text{Is the correct assignment in Group A?}\]After the first question, only 3 possibilities would remain. A second question would reduce this to at most 2, and a third would identify the correct one.
Returning to the original setting, one of these bits is ‘foggy’, because $R$ answers at random. At first glance, this suggests that any answer from R is useless, but this is not quite true. We begin by asking $G_1$ the following question:
\[\text{Is it true that $G_2$ is $R$?}\]The answer leads to the following chain of conclusions:
- If the answer is Yes, then either it is true and $G_2 = R$, or it is a lie, which implies $G_1 = R$. In either case, we conclude that $G_3 \ne R$.
- Similarly, if the answer is No, then $G_2 \ne R$.
- In either case, we have identified at least one goddess who always speaks the truth. From this point on, we can direct all remaining questions to her.
- We are also left with only 4 possible permutations. For instance, if $G_2 \ne R$, then both $(T, R, F)$ and $(F, R, T)$ are eliminated.
We are now done, because two questions are enough to determine which of the remaining 4 permutations is correct!
Addendum: Is it a Solution or the Solution?
The proverbial careful reader might have noticed that the question we asked $G_1$ in the previous section was somewhat arbitrary. It does the job, but is it really necessary?
Let us take a step back. Any question we ask is, in effect, meant to identify a subset of permutations of $ T,F,R $ containing the true arrangement. In this sense, it can be viewed as equivalent to a question of the form:
\[\text{Does the correct permutation belong to the set } \mathcal{S} \text{?}\]where $\mathcal{S}$ may be any subset of the 6 possible permutations. Since each permutation either belongs to $\mathcal{S}$ or not, there are $2^6 = 64$ possible questions.
What Makes a First Question Work?
This boils down to two simple requirements:
-
It must leave us with at most 4 candidate permutations. Otherwise, two further questions are not enough.
-
We must be able to identify at least one goddess who is not $R$.
Let’s briefly explain why the second condition is necessary. Suppose our question concerns the subset
\[\mathcal{S} = \{ (R,F,T) , (F,R,T), (F,T,R)\}.\]and the answer is Yes. The diagram below shows which permutations remain possible depending on whether the goddess lies or not. Remember that if $G_1$ lies, then necessarily $G_1 = R$.
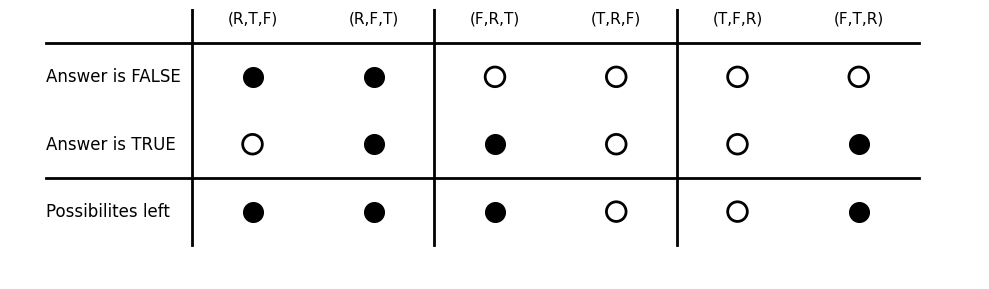
Now, regardless of the second question, we are not guaranteed to eliminate 2 candidate permutations. Any of the goddesses may still be $R$, so if we direct the second question, say, to $G_2$, the permutation $(F,R,T)$ always remains possible.
If $G_2 \not= R$, then the answer can at best split the remaining 3 permutations into two groups and eliminate one of them. Since we cannot guarantee that $G_2 \not= R$, at least 3 permutations must still be considered: 1 arising from $G_2=R$ and 2 from $G_2\not=R$. This is too many to resolve with a single remaining question.
The same argument applies if we direct the second question to $G_1$ or $G_3$ instead.
Counting the Possible Solutions
We now understand the conditions that the first question must satisfy. Let us count the valid choices of $\mathcal{S}$, the subset of permutations specified by the question to $G_1$. First, whether $\mathcal{S}$ contains $(R,F,T)$ or $(R,T,F)$ doesn’t matter, since both remain possible anyway; at this stage, we cannot exclude $G_1=R$. Among the remaining 4 permutations, we must distinguish between the cases $G_2=R$ and $G_3=R$, so that we can identify a non-$R$ goddess and direct the remaining two questions to her.
In summary, any valid subset $\mathcal{S}$:
-
May contain $(R,F,T)$ or not.
-
May contain $(R,T,F)$ or not.
-
Must contain either the 2 permutations corresponding to $G_2=R$ or the 2 permutations corresponding to $G_3=R$, but not all four.
This gives 8 valid first questions in total, so $8/64=12.5 \%$ of all possible choices lead to a complete solution.
On the other hand, all of these questions serve the same purpose: to quickly isolate a truthful goddess we can rely on. In that sense, whether the puzzle has a ‘unique’ solution is largely a matter of interpretation.
]]>